Deep Leaning Project: Image Captioning
- Abstract: Inspired by current technology, helping visually impaired people to know their surroundings by experiencing the speech context of images using automatic caption generation is in great demand. Generation of new sentences using the combination of both Convolution neural networks and Natural processing is challenging. In this procedure, the model should understand the image and generate a sentence that describes the image. In this project, we have implemented solutions for image captioning using merge architecture and transformers. This project uses encoder and decoder architecture, where the encoder has images, that are used to train CNN models such as Xception, ResNet, and MobileNet. For the decoder, we propose Long short-term memory (LSTM), Gated Recurrent Unit (GRU), LSTM with attention, and transformers. Experimental results on the FLICKR 8k dataset show that Xception-LSTM-attention-FF had outperformed all other models using the evaluation metric called the BLEU score.
- Datasets: Flickr8K
- Models:
- Merge Architecture: Xception-LSTM-FF, Xception-LSTM-additive attention-FF, Xception-GRU-FF, Resnet50-LSTM-FF, Resnet50-LSTM-additive attention-FF, Resnet50-GRU-FF,
- Encoder-Decoder Architecture: Mobilenet-transformer
- My contribution: merge architecture (Xception models)
- Report: Click Here
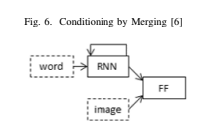
Merge Architecture
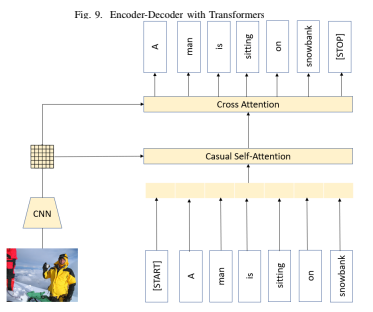
Encoder-Decoder Architecture
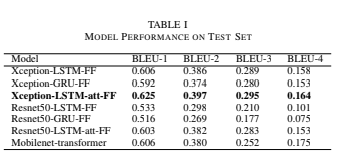
Performance
- Technologies: researching, deep learning, Keras, NLP, Sequence Processing
- Category: Data Science